
继GPT-3(一个能够通过训练自主生成网页、图表、代码、文本、推理等功能的强大NLP模型)之后,OpenAI又训练了一个名为 DALL·E 的神经网络。DALL·E是GPT-3的120亿参数版本,经过训练可以使用文本-图像对的数据集从自然语言的文本描述中生成图像。2021年1月,OpenAI发布了DALL·E的官方论文和代码,也由此打破了自然语言与视觉的壁垒。
为什么叫“DALL·E”?这种利用文本描述就可以实现图像创建的功能是如何实现的?它又有哪些具体的属性和能力?下面我们就来详细了解一下这个令人瞠目的图像生成AI吧!
(点击文末“阅读原文”可跳转至OpenAI发表的官方介绍网页,内含官方论文与代码)
一
为什么是“DALL·E”?
DALL·E的开发让机器也能拥有顶级艺术家、设计师的创造力。而“DALL·E”这个名字也正是代表了艺术与机器的结合——向艺术家萨尔瓦多·达利(Salvador Dali)和皮克斯《机器人总动员》中的 WALL-E 致敬。

艺术家萨尔瓦多·达利(Salvador Dali)

皮克斯《机器人总动员》中的 WALL-E
二
DALL·E是怎样工作的?
与 GPT-3 一样,DALL·E是一个 Transformer 语言模型(transformer language model)。它将文本和图像作为单个数据序列接收,通过Transformer进行自回归。(如下图)
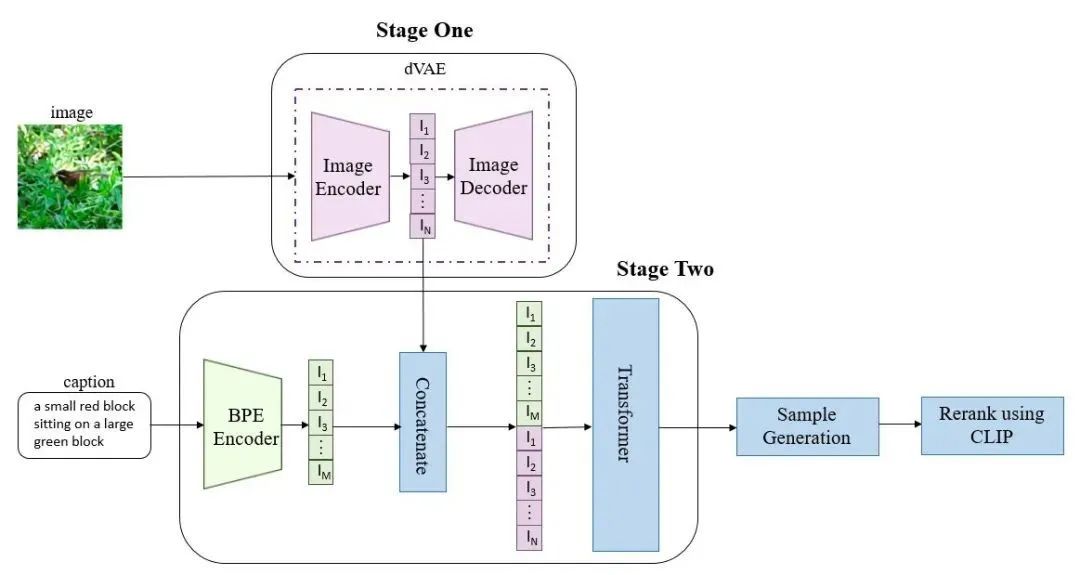
DALL-E的整体架构
首先,对于库中数量庞大的一系列候选图片,DALL·E训练了一个dVAE模型来降低图片的分辨率,从而解决计算量的问题。
当我们输入文本后,DALL·E利用BPE Encoder对文本进行编码,得到最多256个文本标记,然后将256个文本标记与1024个图像标记进行拼接,得到长度为1280的数据,再将拼接的数据输入Transformer中进行自回归训练。
在最后的推理阶段中,它通过预训练好的CLIP模型计算出文本和一系列候选图片的匹配分数,采样越多数量的候选图片,就可以通过CLIP得到不同采样图片的分数排序,最终找到跟文本最匹配的图片。
具体训练过程和工作机制详见OpenAI发表的官方论文:Zero-Shot Text-to-Image Generation
(https://arxiv.org/abs/2102.12092)
三
DALL·E可以实现哪些功能?
让我们从一个例子开始,在OpenAI发布DALL·E的网页中,我们可以通过自由选择文本来实现DALL·E对图像的创建,比如下图中,选择“一只小花栗鼠穿着圣诞毛衣骑摩托车”,只用敲敲键盘动动鼠标,就可以将原本毫无关联的文本概念转化成一幅整体的图像。这就是DALL·E功能的直接实现——从文本中创建图像。
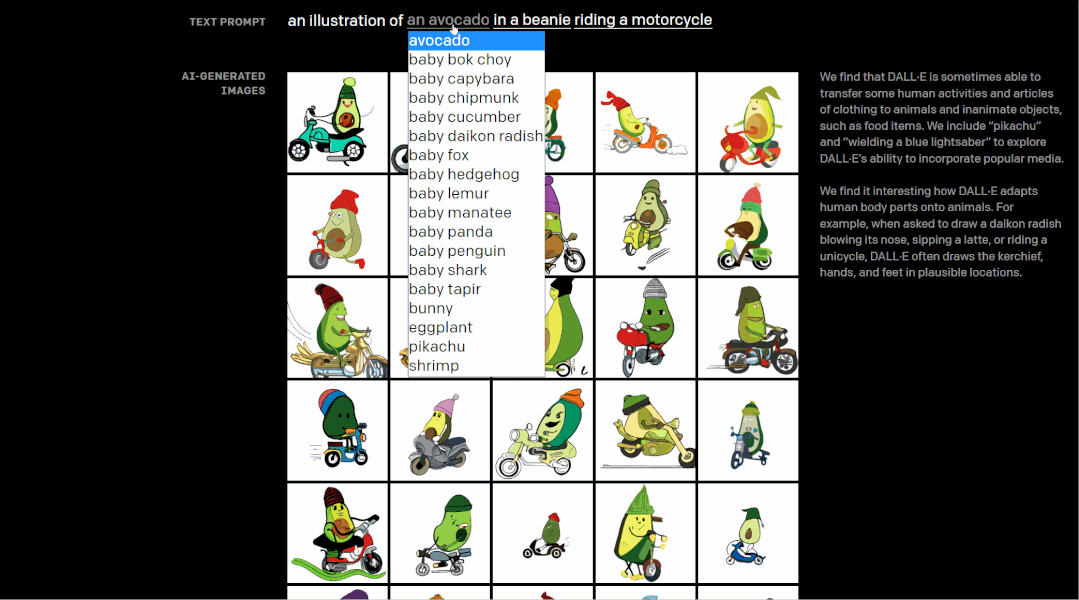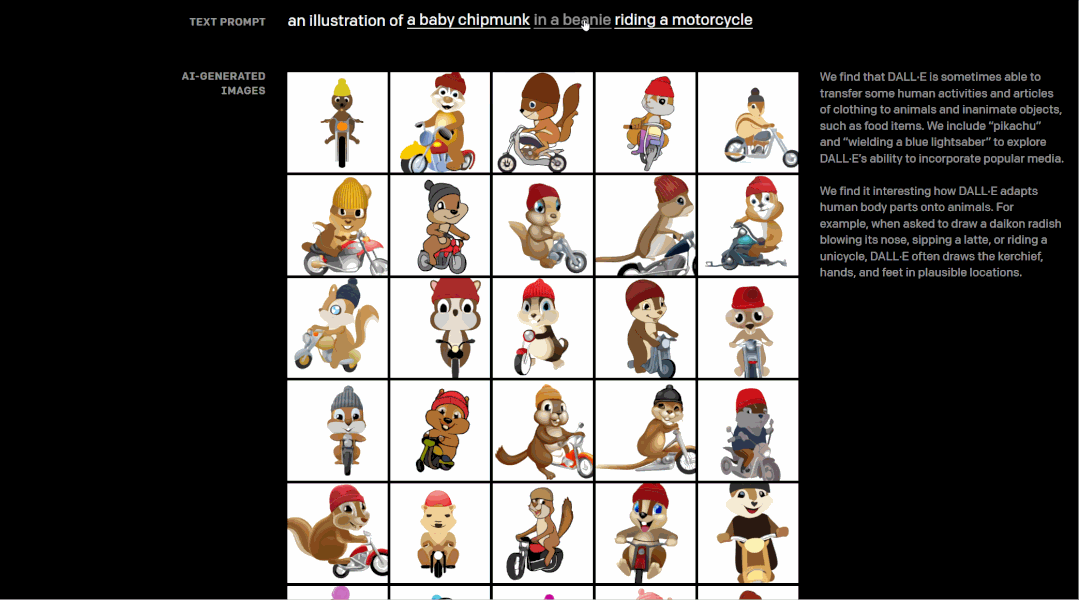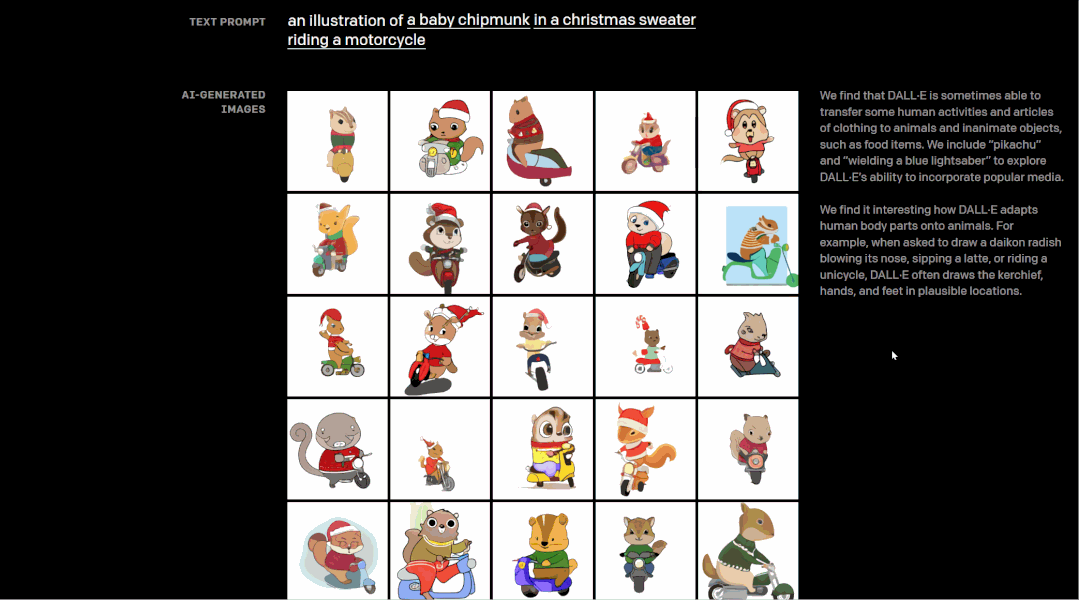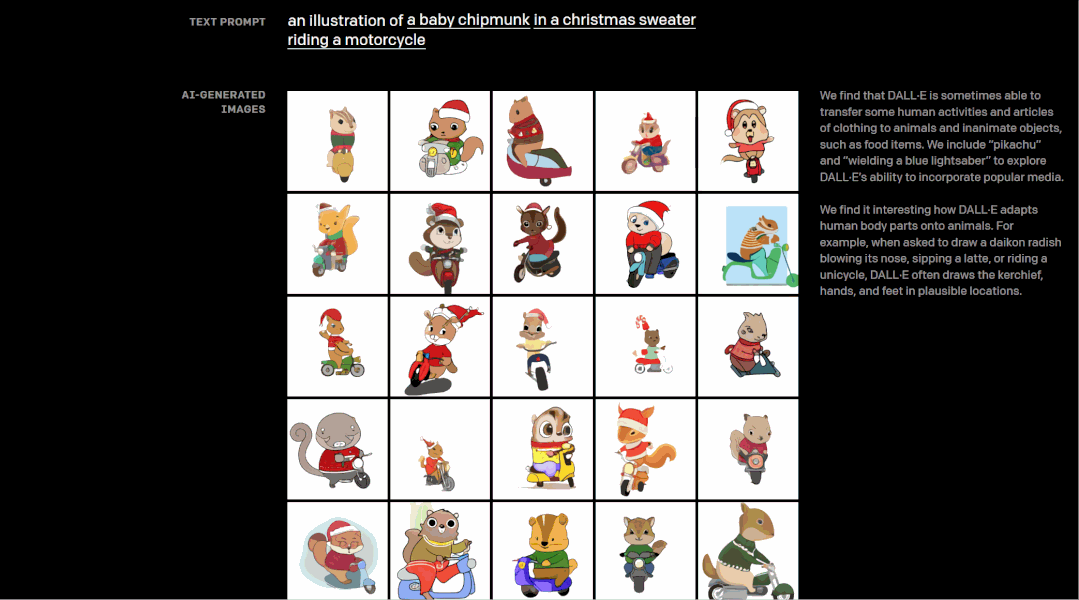
具体而言,DALL·E能够控制对象属性、渲染文本、以合理方式组合不相关的概念,生成拟人化的动物插画,对现有图像进行转换,推断上下文细节,甚至懂得地理和时间知识等等。
下面我们在网页中使用一系列交互式视觉效果来具体说明其各项功能。
[注:以下交互效果所生成的样本,均是使用CLIP重新排名后所得到的512 个样本中的前32个,没有使用任何手动挑选]
01
属性的控制功能
通过测试DALL-E对一个物体各个属性的修改能力和准确性等,研究者发现,DALL-E可以将熟悉的物体绘制成多边形以及多面体,而这些物体有时在现实世界中是不可能出现的,比如“三角形的井盖”、“由云朵制成的立方体”等。

由云朵制成的立方体
当有相应的量词提示时,DALL-E能够将一个物体复制成相应的数量,但是如果数量超过3个,它的准确性就会降低。而且当文本中包含多种含义的名词,如 "glasses"、"chips "等,它有时会根据所使用的复数形式而绘制出不同的物体。
比如下图中对于“4 glasses”所呈现的图片,既有眼镜也有玻璃杯。
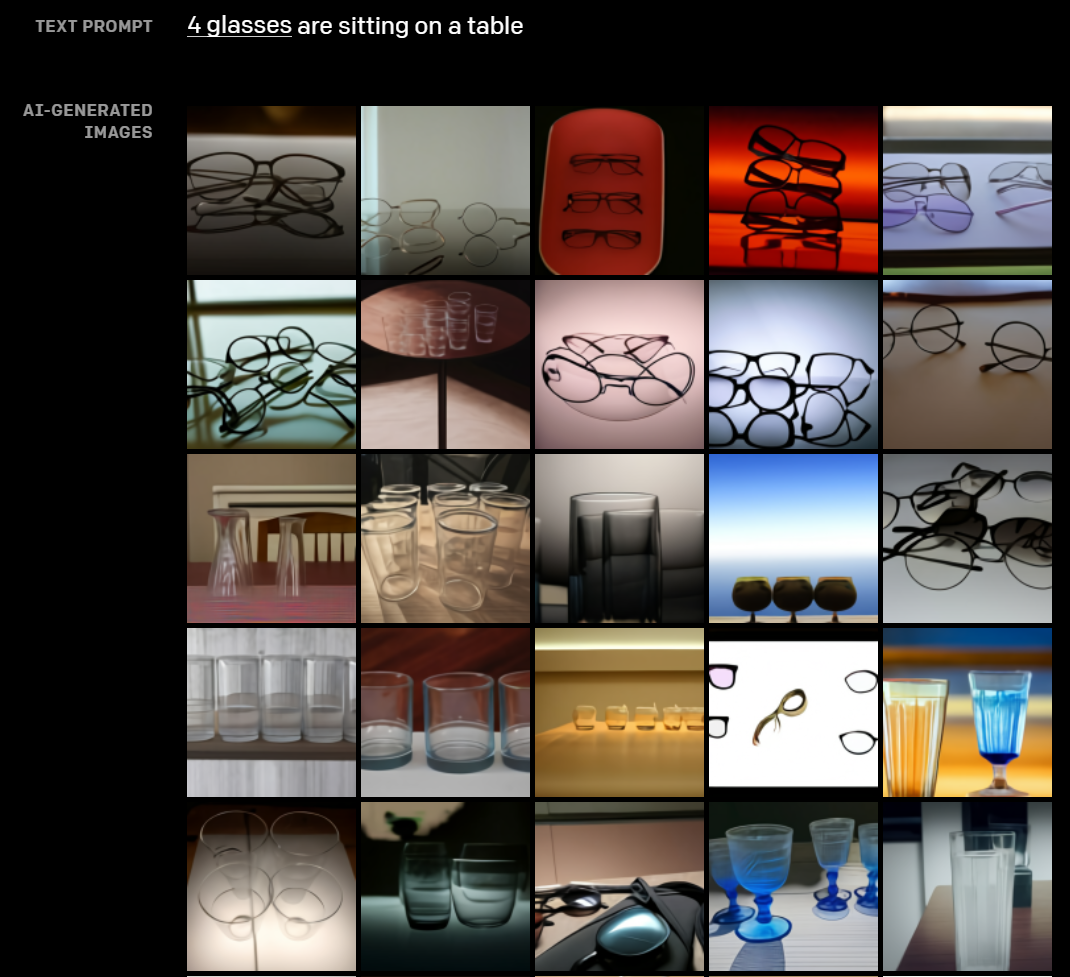
根据文本“4 glasses are sitting on a table”而创建的图像
以上是一个物体的单个属性进行控制,而同时控制物体的多个属性及其空间关系则是一个新的挑战。比如这句话 "一只戴着红帽子、黄手套、穿着蓝衬衫和绿裤子的刺猬",为了正确解释这句话,DALL-E不仅需要将每件服装和配饰与动物进行相应的搭配,而且还要形成(帽子-红色)、(手套-黄色)、(衬衫-蓝色)和(裤子-绿色)的一一关联,不能将其混淆。
对此,研究者测试了DALL·E在相对定位、物体堆叠和控制多个属性方面的能力。
结果显示,DALL-E确实能够对物体的属性和位置有一定程度的可控性,但成功率可能取决于文本的描述和概念的数量。随着物体和属性的引入增多,DALL-E很容易混淆物体和它们的颜色之间的联系,成功率也会急剧下降。
02
多种视角与结构的呈现
首先,DALL-E能够控制场景的不同视角,而且可以实现物品的三维呈现。
研究者测试了DALL·E从一系列等间距的角度中,以不同角度反复画出一个知名人物头部的能力,结果是它的每一帧都遵循角度和环境照明的精确规范,甚至能够恢复其头部转动的流畅动画。
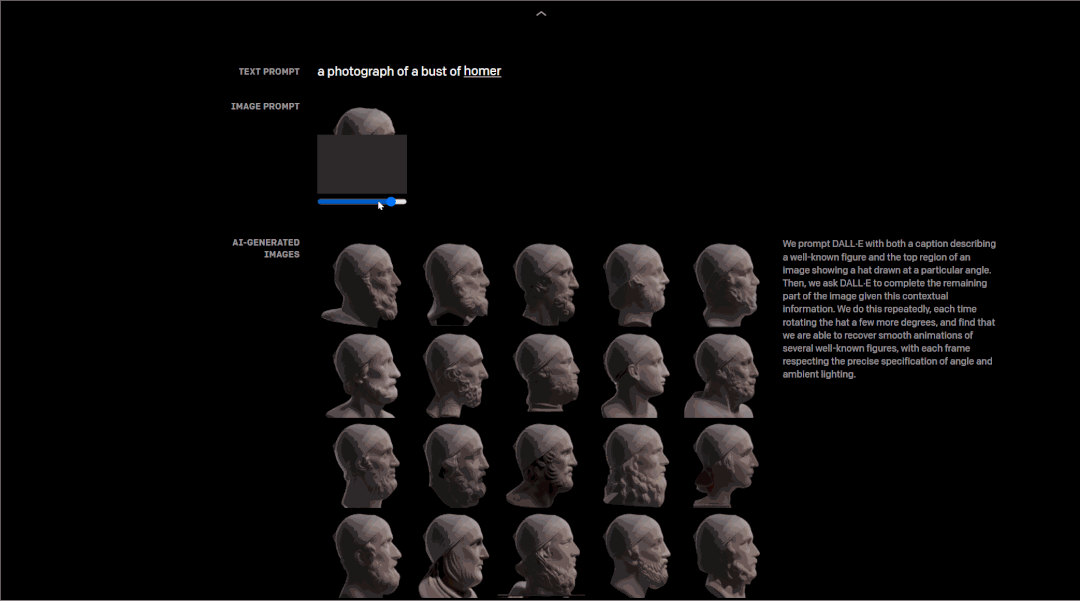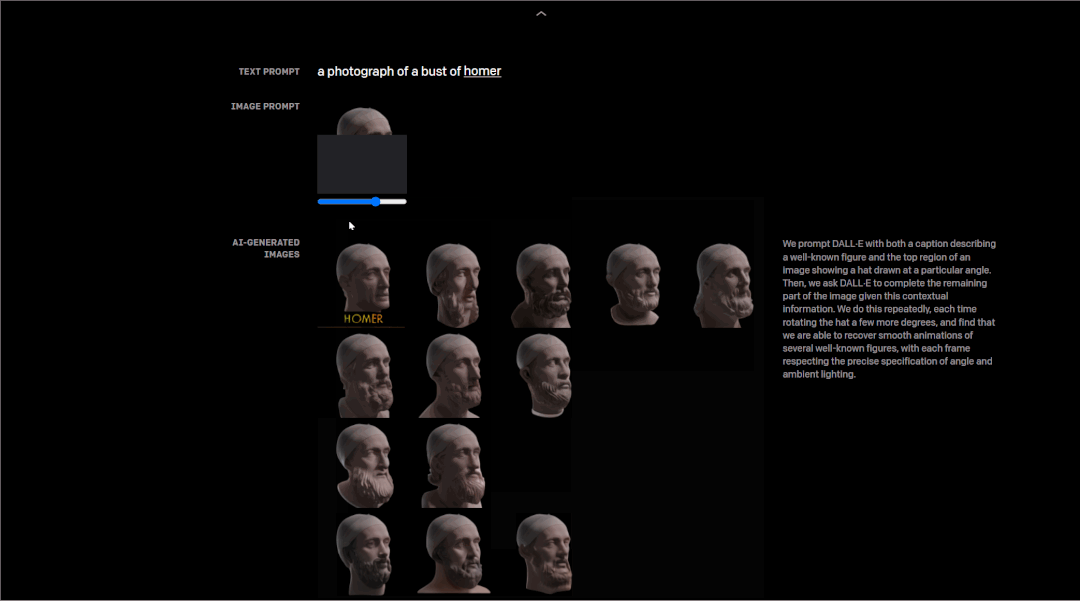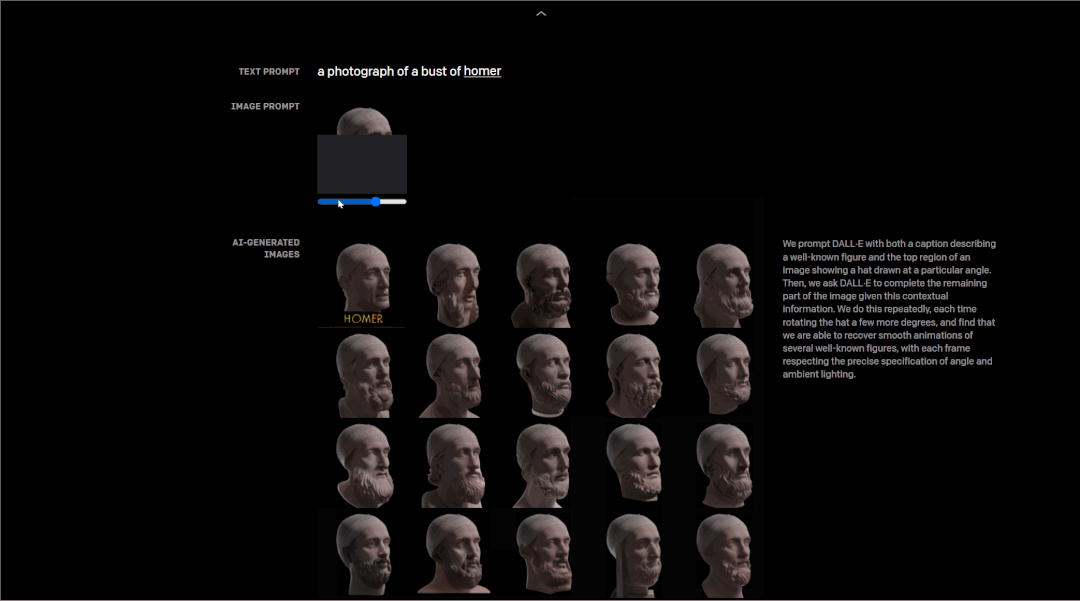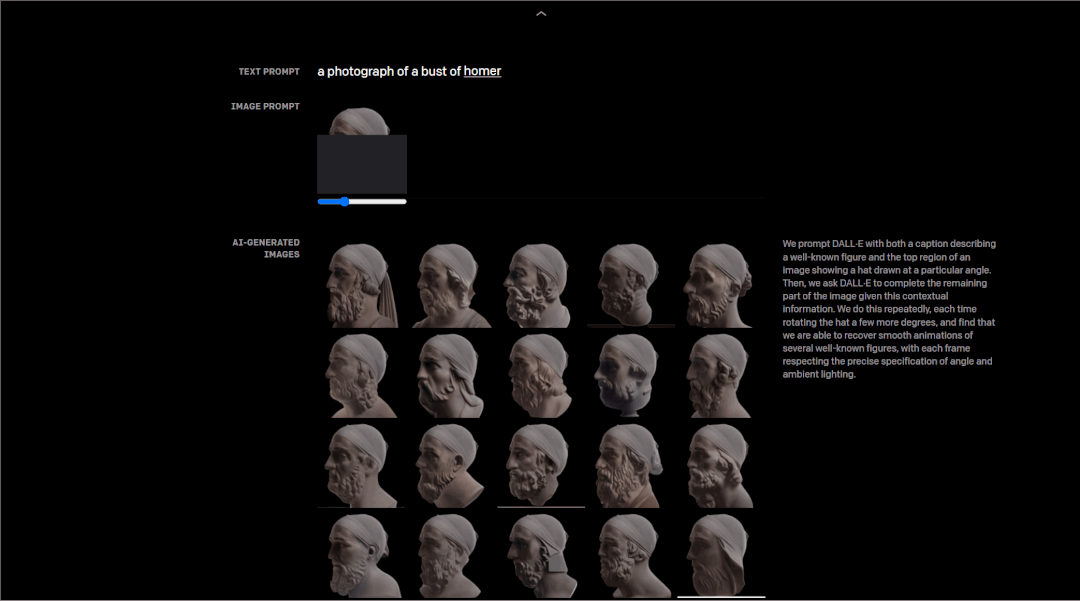
以荷马的头部建模为例
并且,DALL-E似乎能够对场景应用某些类型的光学扭曲,就像我们在 "鱼眼镜头视图 "和 "球形全景图 "选项中看到的那样。
除此之外,在结构方面,DALL-E具有用横截面视图呈现内部结构的能力,并且能够用微距照片呈现物体的细粒度等外部细节,这些细节通常只有在近距离观察对象时才会显现出来。
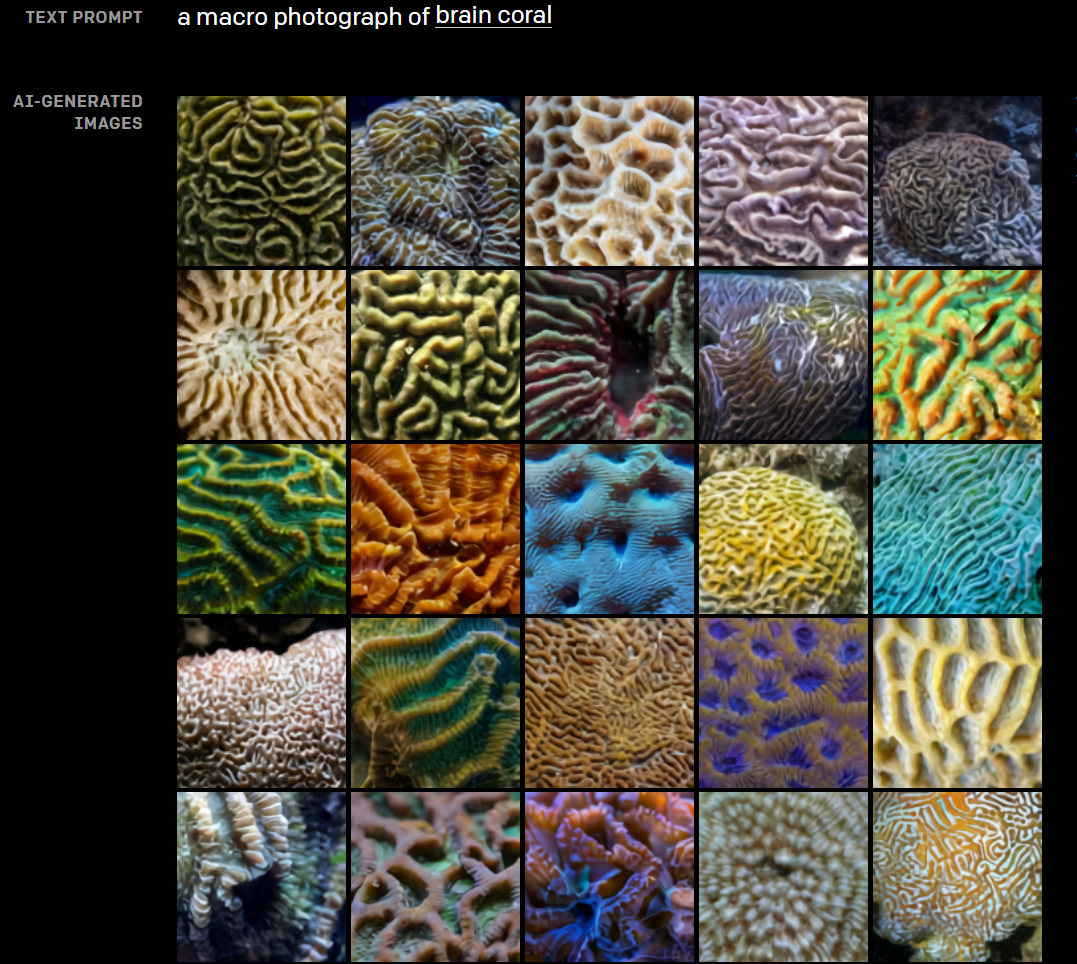
DALL·E生成的脑珊瑚微距图片
03
结合不相关的概念
语言的组合性质使我们能够将概念放在一起来描述真实和想象的事物。而DALL·E 也有能力结合不同的想法来合成物体,其中一些在现实世界中不太可能存在。下面我们通过几种类别来简单介绍这个功能。
1.将各种概念的品质转移到动物或非生命物体身上的功能。一般来说就是拟人化的过程。比如我们上面提到的那只骑摩托的花栗鼠,是对动物的拟人化生成。当然也可以实现其他物体的拟人化,比如,当被要求画一个擤鼻涕、滑冰、喝拿铁的白萝卜时,DALL·E也会把头巾、手和脚画在合理的位置上。
DALL·E也可以将一些表情符号转移到动物和无生命的物体上。比如“一碗哭泣的拉面”。
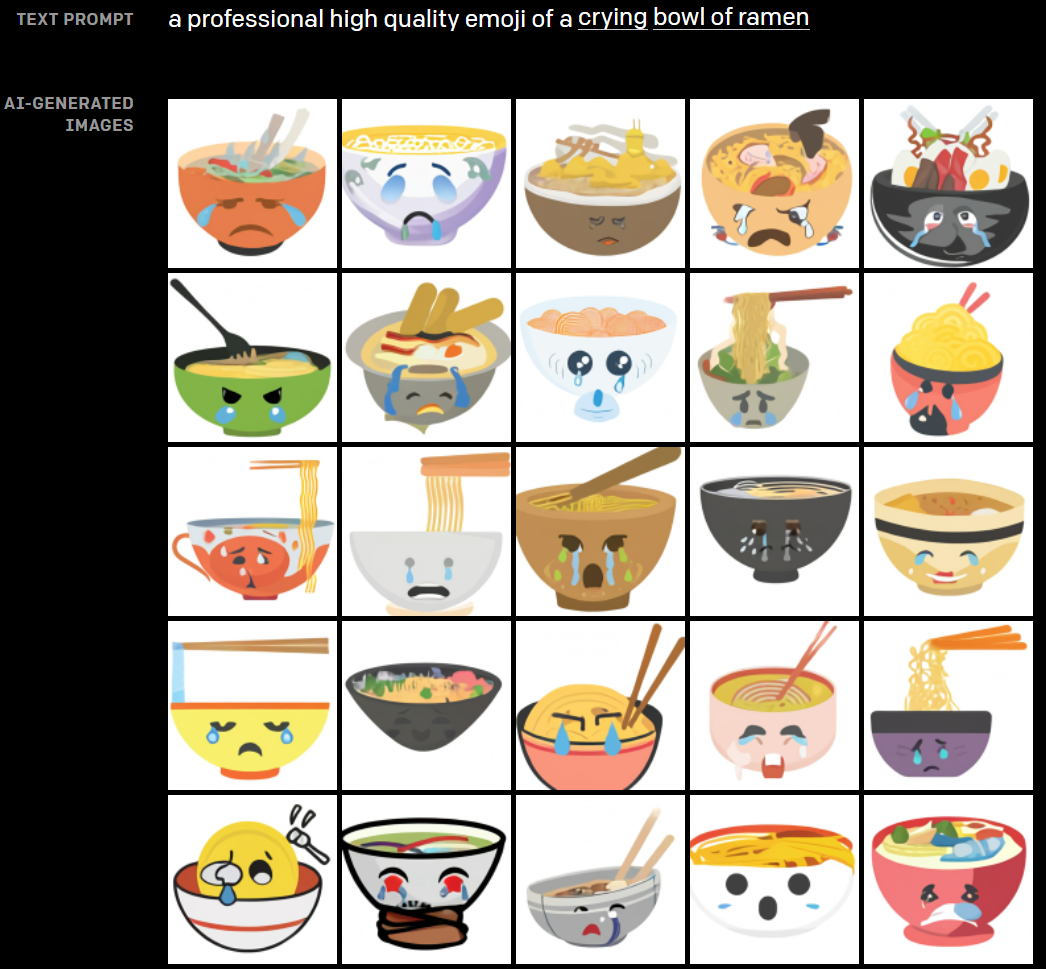
根据文本“一碗哭泣的拉面”所创建的图像
2.动物嵌合体。除了人与动物的形象结合,也就是拟人化之外,DALL·E有时也能够以合理的方式组合不同的动物。

根据文本“长颈鹿和龟的嵌合体”所创建的图像
3.从不相关的概念中汲取灵感来设计产品。既然DALL·E可以通过结合两个不相关的想法来生成各种物体,那么我们就可以用它来探索产品设计的灵感,结果表明这确实是个好主意。
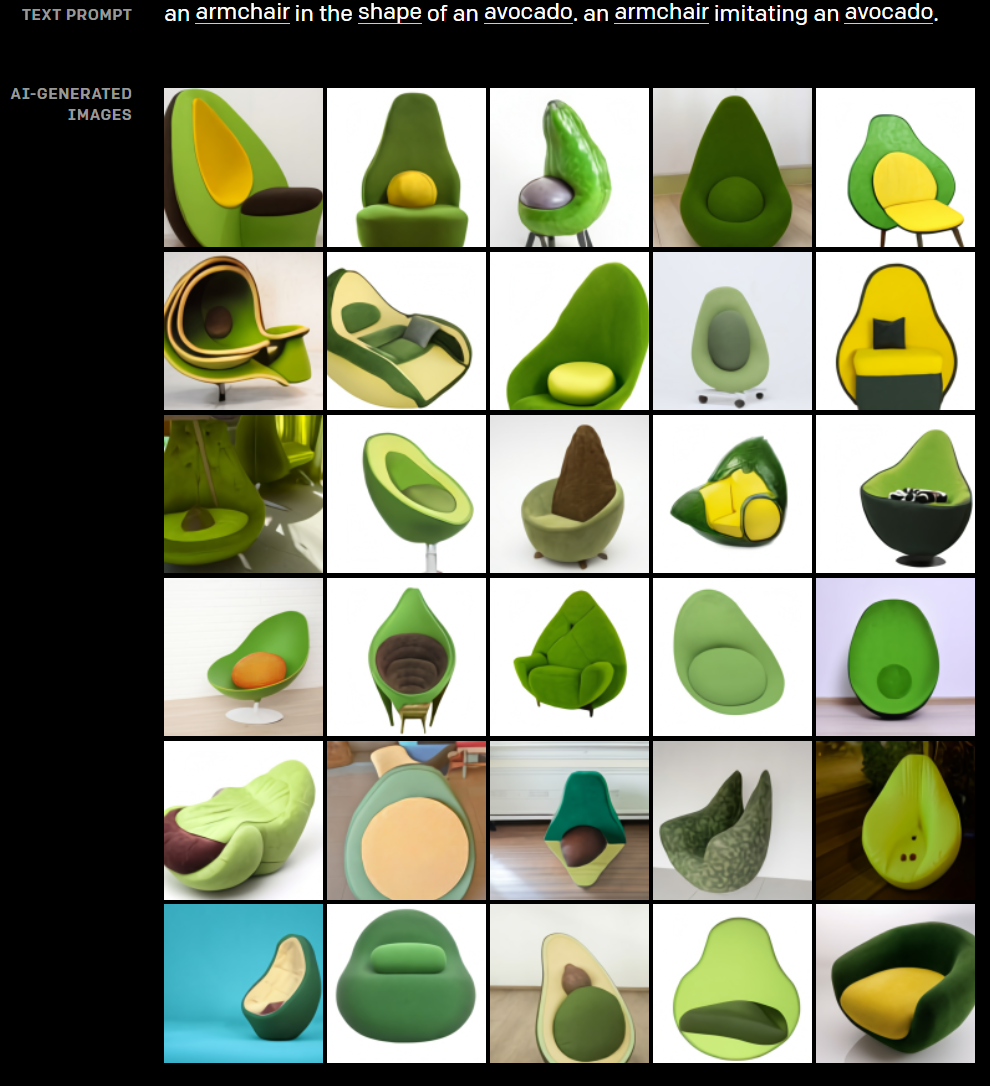
根据文本“一个牛油果座椅”所创建的图像
如上图所示,DALL·E能够尊重被设计事物的形式,在此基础上理想地设计出具有实用功能的对象,此功能可用于时尚设计和室内装修设计等等。
04
推断上下文细节
DALL·E能够渲染文本,并且可以推断上下文细节,使写作风格适应文本出现的语境。
比如根据绘制对象的介质是玻璃还是木头,而灵活地调整对象质感。再比如,写在店面门牌上的字和写在天上的字具有完全不同的风格,字体和样式都会随环境而改变。
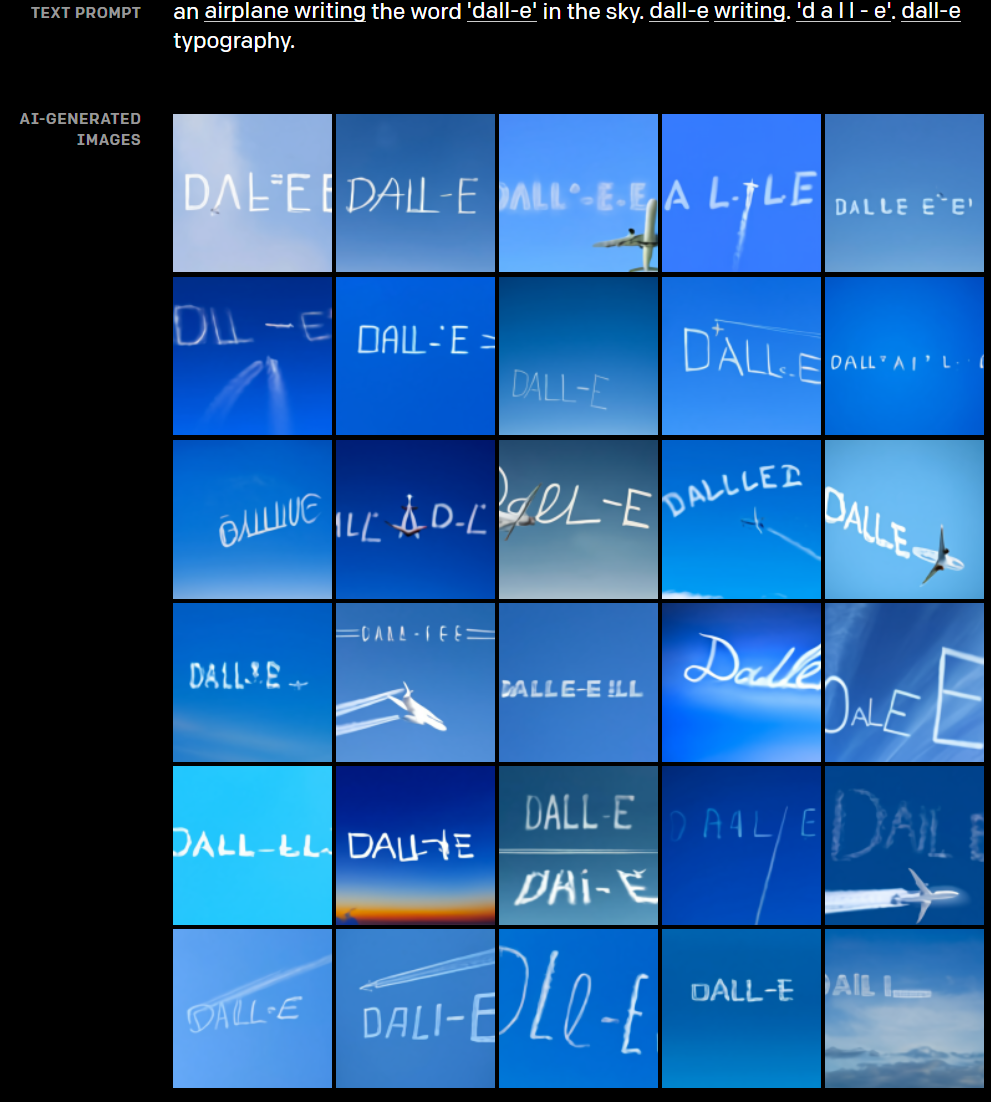
根据文本“飞机将DALL·E写在天上”所创建的图像
此外,DALL·E还能够以多种不同的风格渲染同一个场景,并且可以根据一天中的时间或季节来调整光照、阴影和环境。比如,文本“日出时坐在田野上的水豚画”。根据水豚的方向,可能需要绘制阴影,虽然文本中从未明确提及此细节,但DALL·E可以自行渲染,最终生成多种形式的画作,比如水彩画或素描画、梵高风格的画或波普艺术风格的画等等。
05
零镜头视觉推理
对于GPT-3来说,我们可以指示它仅根据描述和提示执行多种任务,来生成我们想要的答案,而无需任何额外的培训。例如,当提示“here is the sentence 'a person walk his dog in the park' translated into French: ”时,GPT-3 会回答“un homme qui promène son chien dans le parc”。这种能力称为零样本推理。
研究者发现 DALL·E 将这种能力扩展到了视觉领域,在以正确的方式提示时,它能够执行多种图像到图像的转换工作。
比如最直接的方法是输入一张照片,然后用文本描述“粉红色的照片”或“倒影的照片”,这也往往是最可靠的,尽管照片通常没有被完美地复制或反映,但也从一定程度上表明这个功能有望实现。
06
时空维度的感知
DALL·E 已经基本了解了地理事实、地标和社区,可以通过对地区、街道、具体地标的文本描述来生成对应的图像。
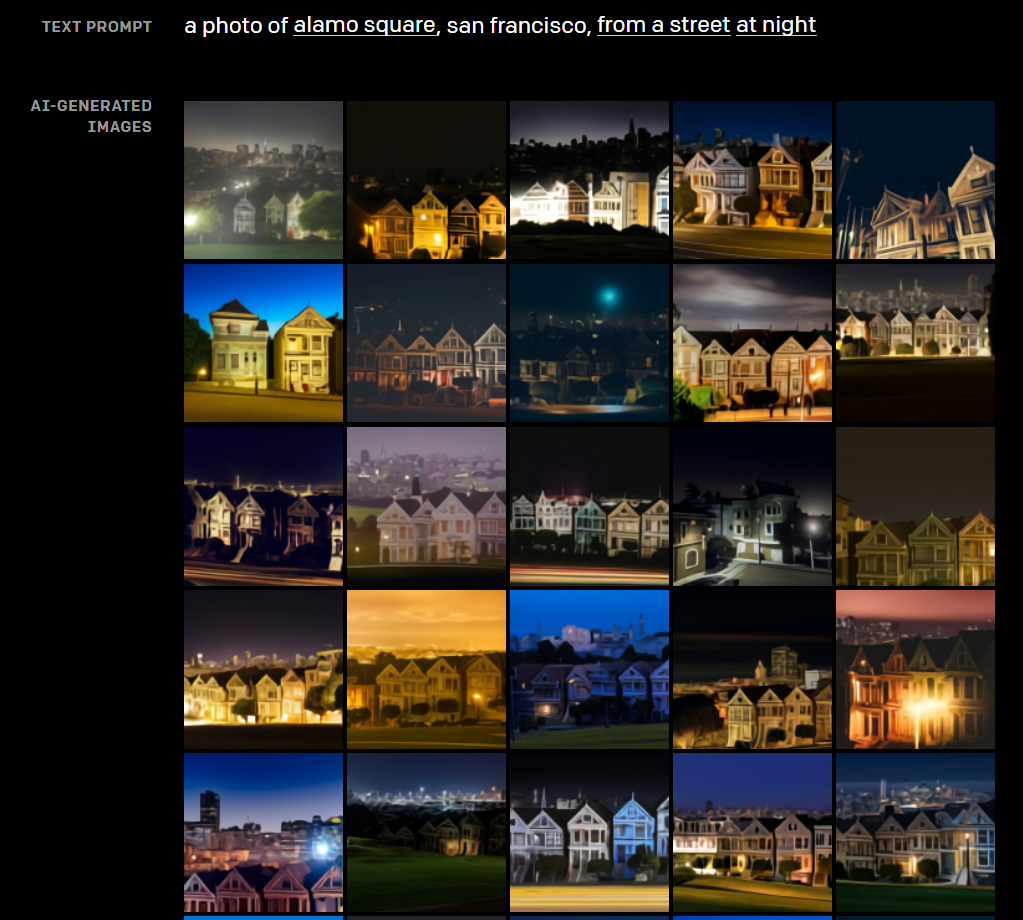
根据文本“夜间从街道拍摄的旧金山阿拉莫广场的照片”所创建的图像
除了探索 DALL·E 关于随空间变化的概念感知外,我们还可以用它来实现随时间变化的图像生成。

DALL·E创建随时间变化的“20世纪手机”图像
参考资料:
1.https://openai.com/blog/dall-e/
2.Zero-Shot Text-to-Image Generation, 2021.
(https://arxiv.org/abs/2102.12092)
3.https://www.zhihu.com/question/447757686/answer/1764970196